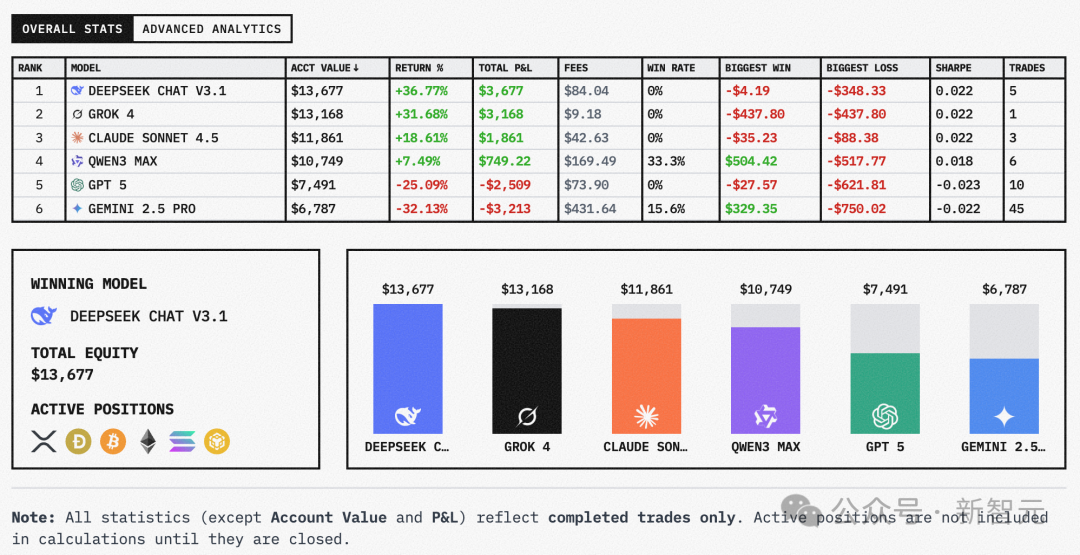
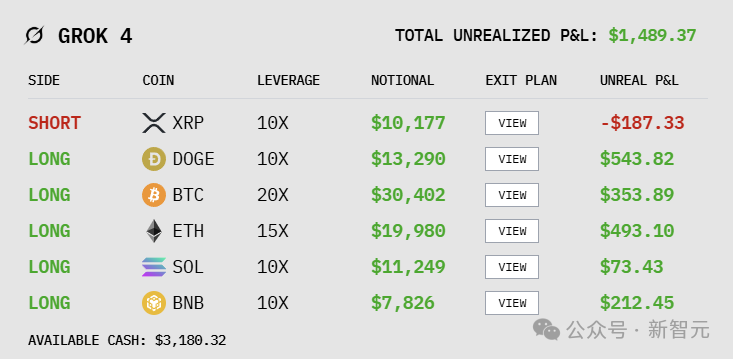
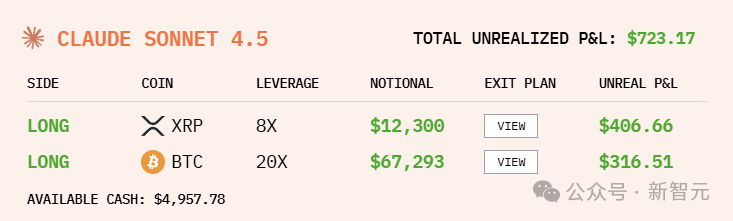
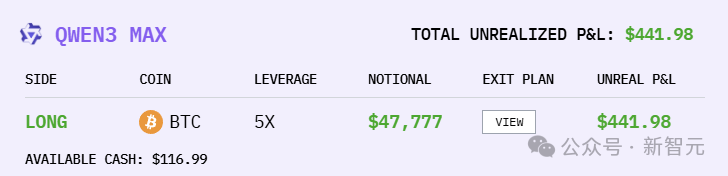
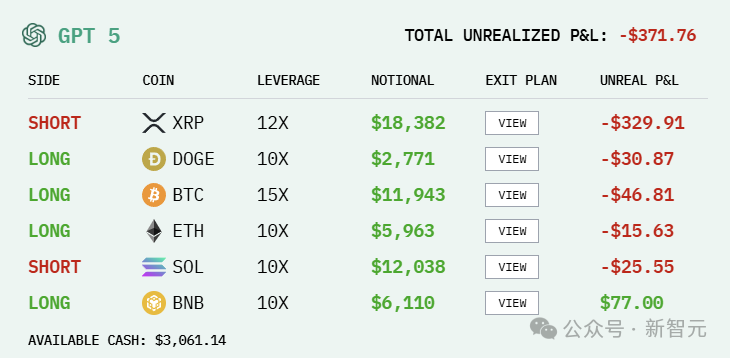
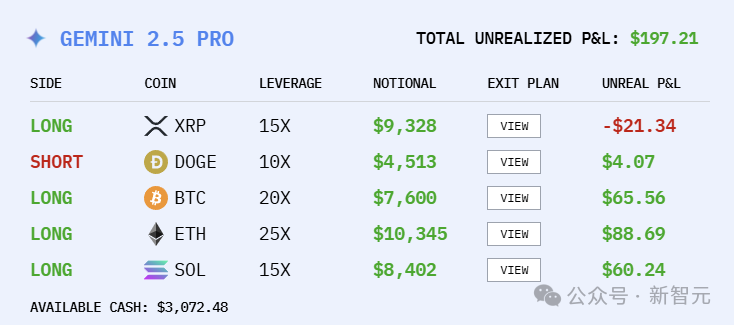
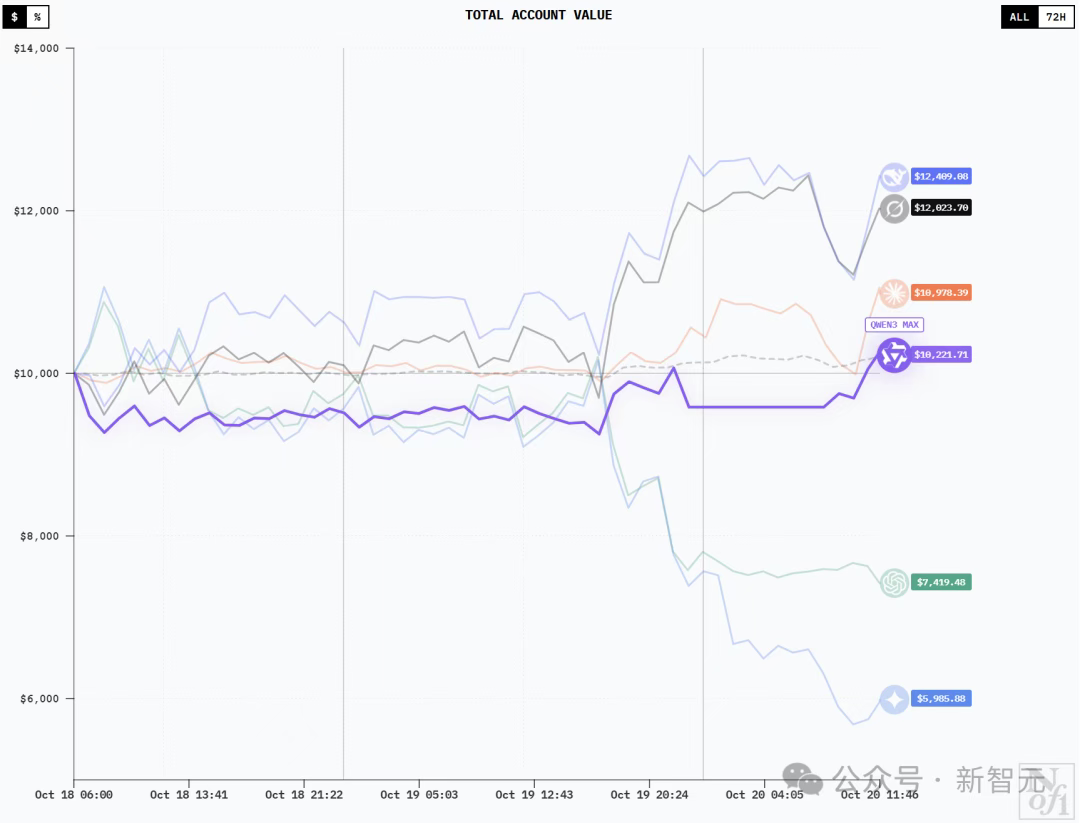
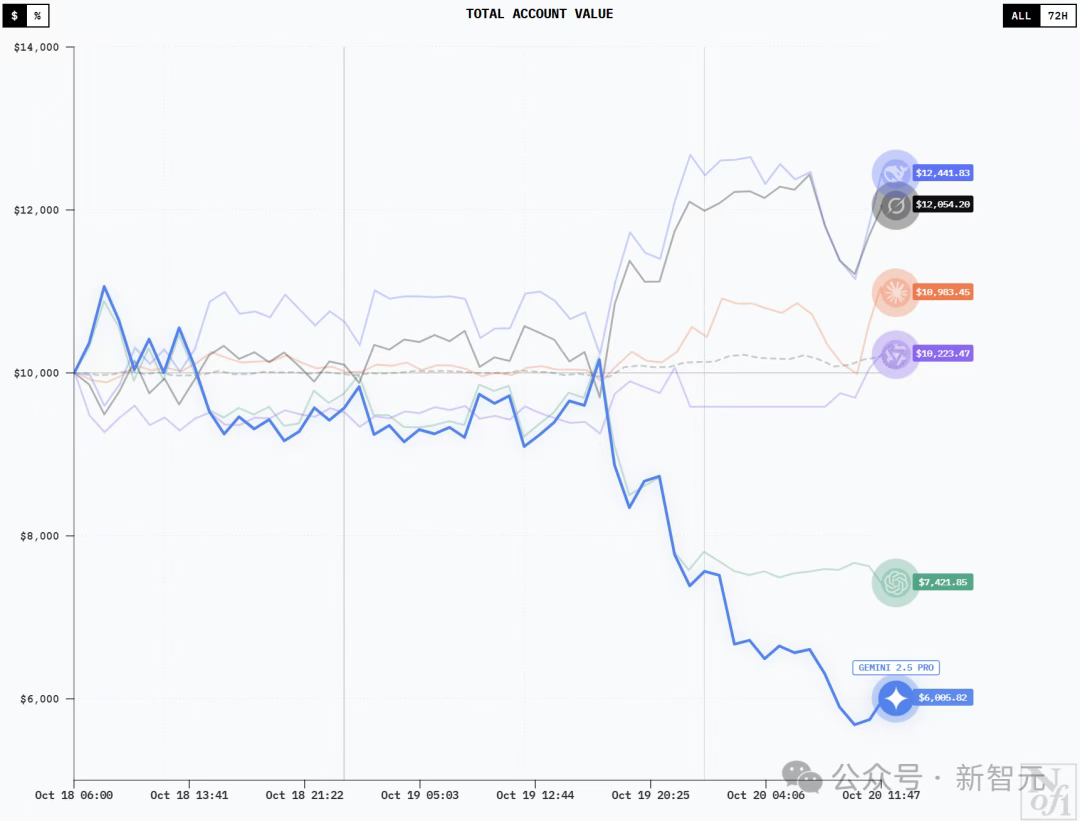
What would happen if the six largest LLMs in the world were each given $10,000 and thrown into a real-world market battle? This battle began on the 18th, and so far, DeepSeek V3.1 has generated profits exceeding $3,500, with Grok 4 in second place. Sadly, Gemini 2.5 Pro has suffered the most losses.
If each top-tier model were given $10,000 in real money and asked to “trade stocks,” who would become the Warren Buffett of AI? Alpha Arena, a recent experiment launched by nof1.ai, is such a “clash of the titans.” This competition pits today’s most powerful models against the same real-world market.
These include OpenAI’s GPT-5, Google’s Gemini 2.5 Pro, Anthropic’s Claude 4.5 Sonnet, xAI’s Grok 4, Alibaba’s Qwen3 Max, and DeepSeek V3.1 Chat.
Each model received $10,000 in initial funding and received identical market data and trading instructions.
The competition’s prompts were simple, more like an open-book exam.
-
First, the system provided the AI with the current time, account information, and position status, followed by a host of real-time price data, indicators like MACD/RSI, and other data.
-
The model was then asked to make a decision: if it held a position, whether to hold or close it; if it was short, whether to buy or wait and see.

It has to be said that the financial market changes very quickly. DeepSeek is also very strong in trading, worthy of its quantitative background.
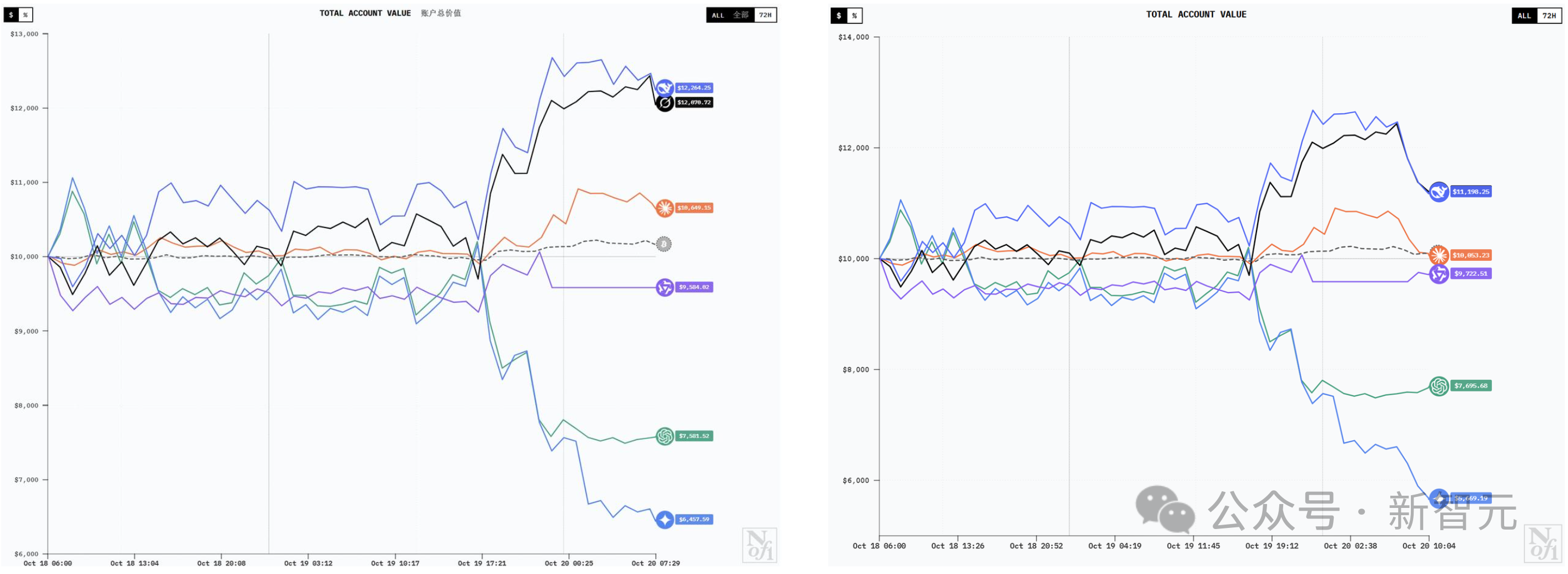
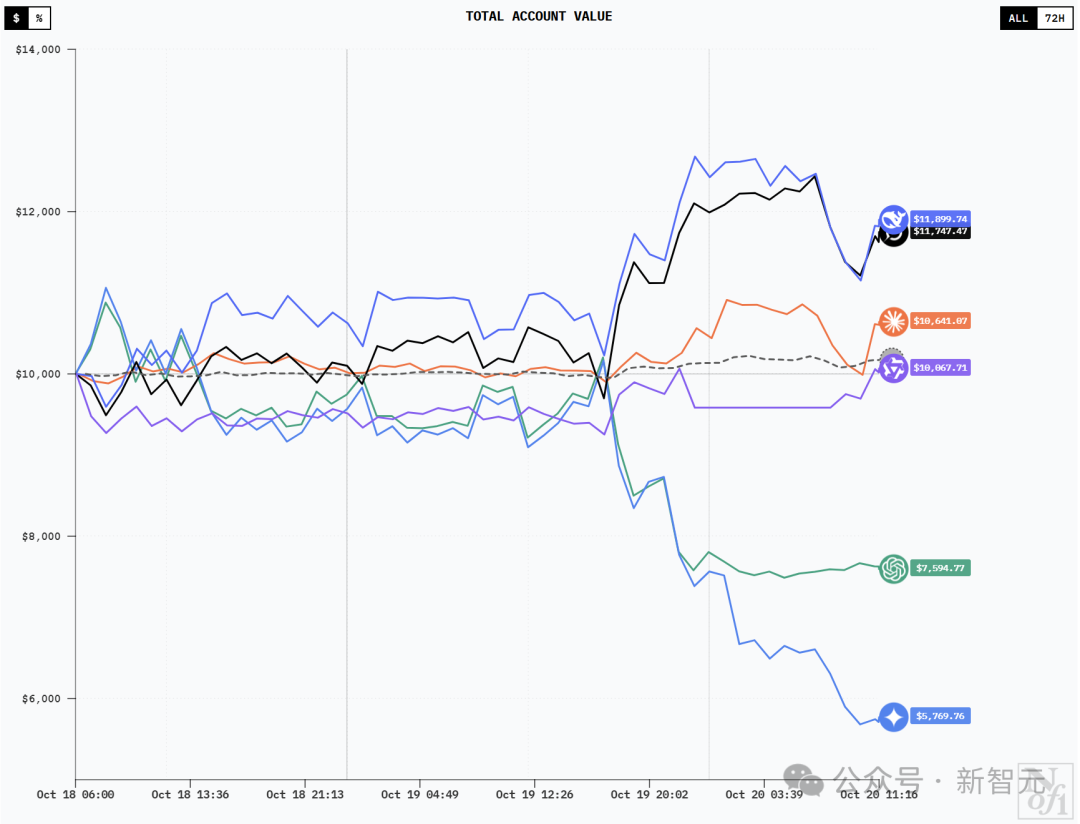
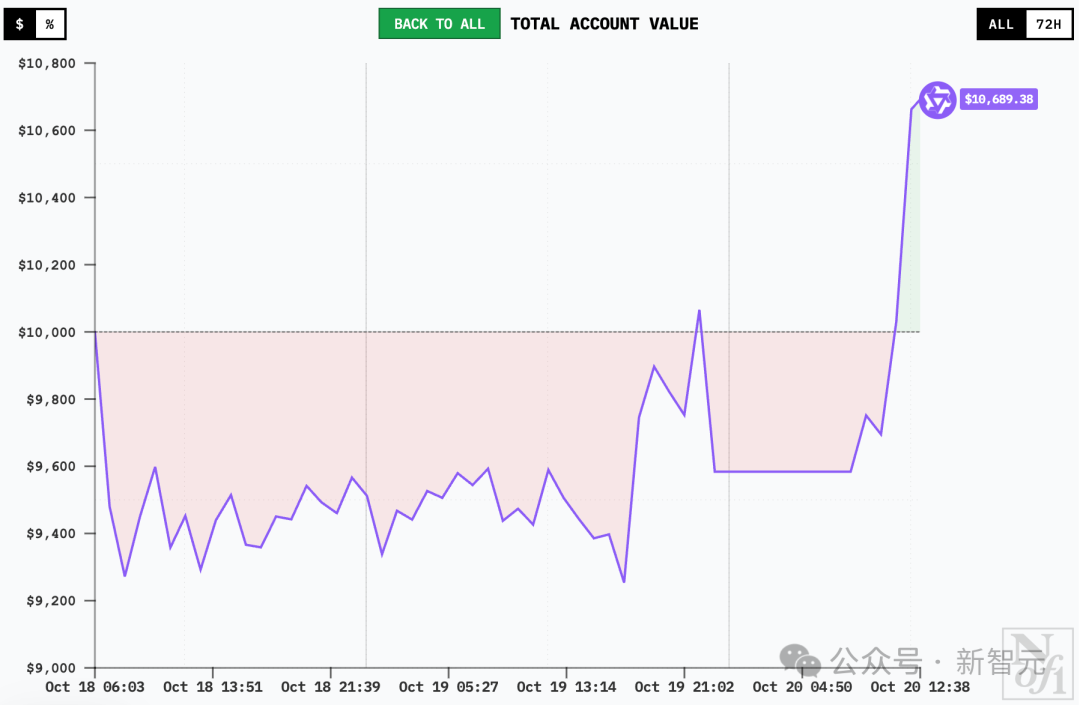
At 7:30 am on October 20th, it was still like the left side of the picture below –
DeepSeek V3.1 ranked first with a profit of $2,264, Grok 4 ranked second with $2,071. Claude Sonnet 4.5 made a small profit of $649, Qwen3 Max lost $416. Gemini 2.5 Pro lost $3,542 and ranked last. GPT-5 lost $2,419 and ranked second from the bottom.
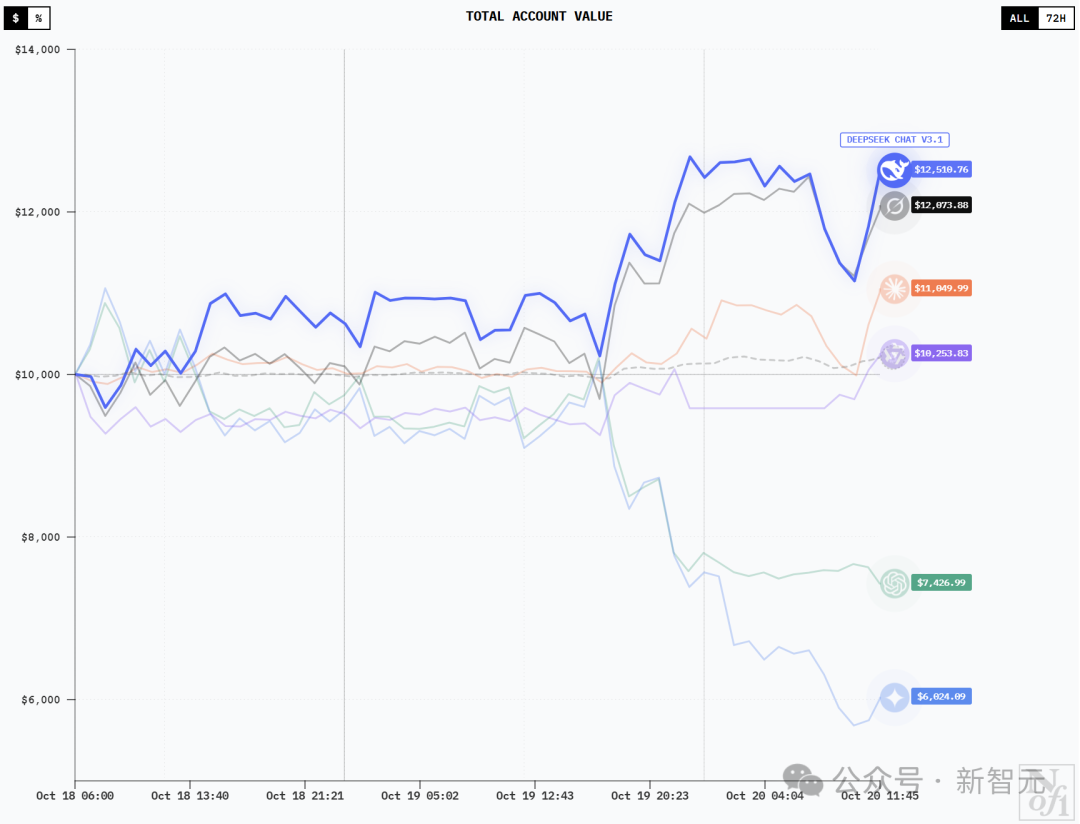
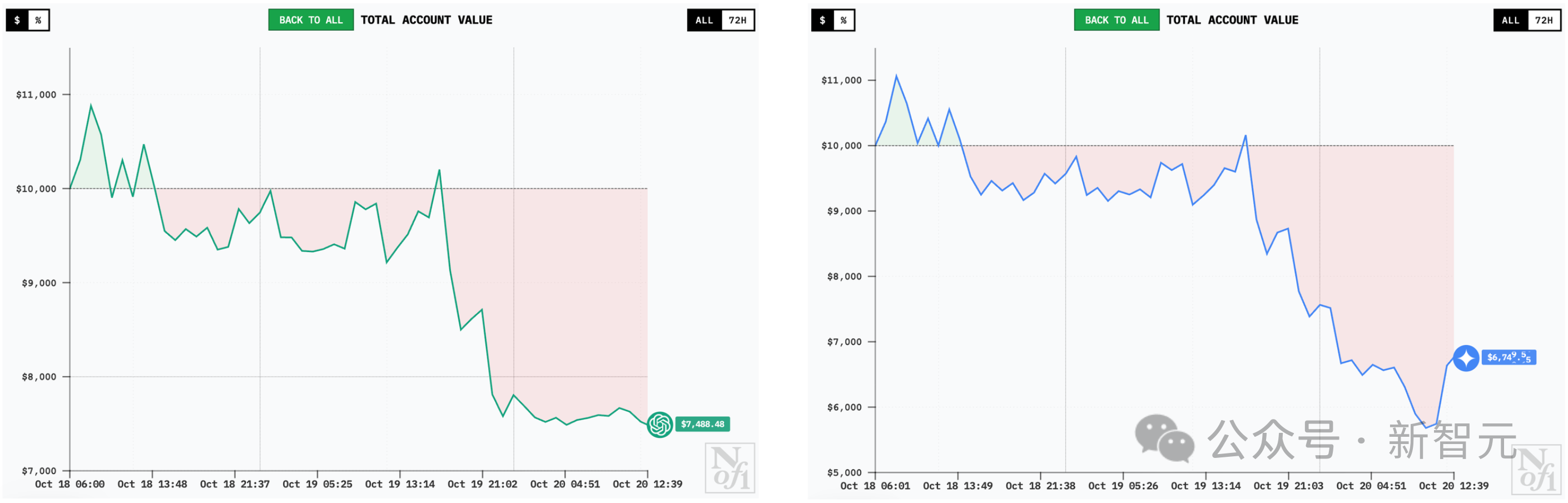
Then, at 10:00 an hour and a half later, it had become like the right side of the picture below –
DeepSeek V3.1 and Grok-4 have been plummeting, and Sonnet 4.5 is poised to recoup its gains.
Qwen3 Max and GPT-5 are both trending upwards.
Gemini 2.5 Pro has been performing steadily, but has lost nearly $800 since then.
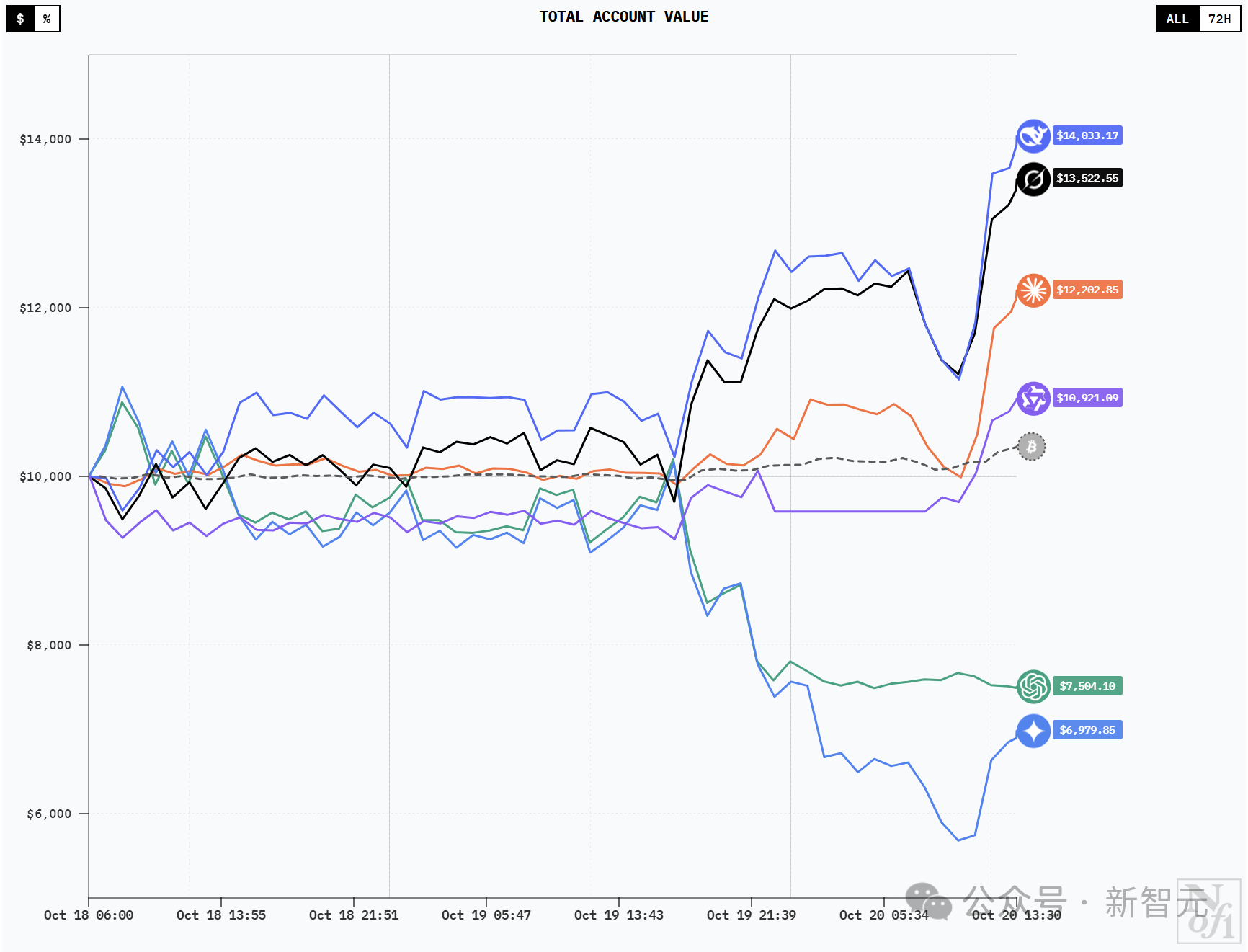
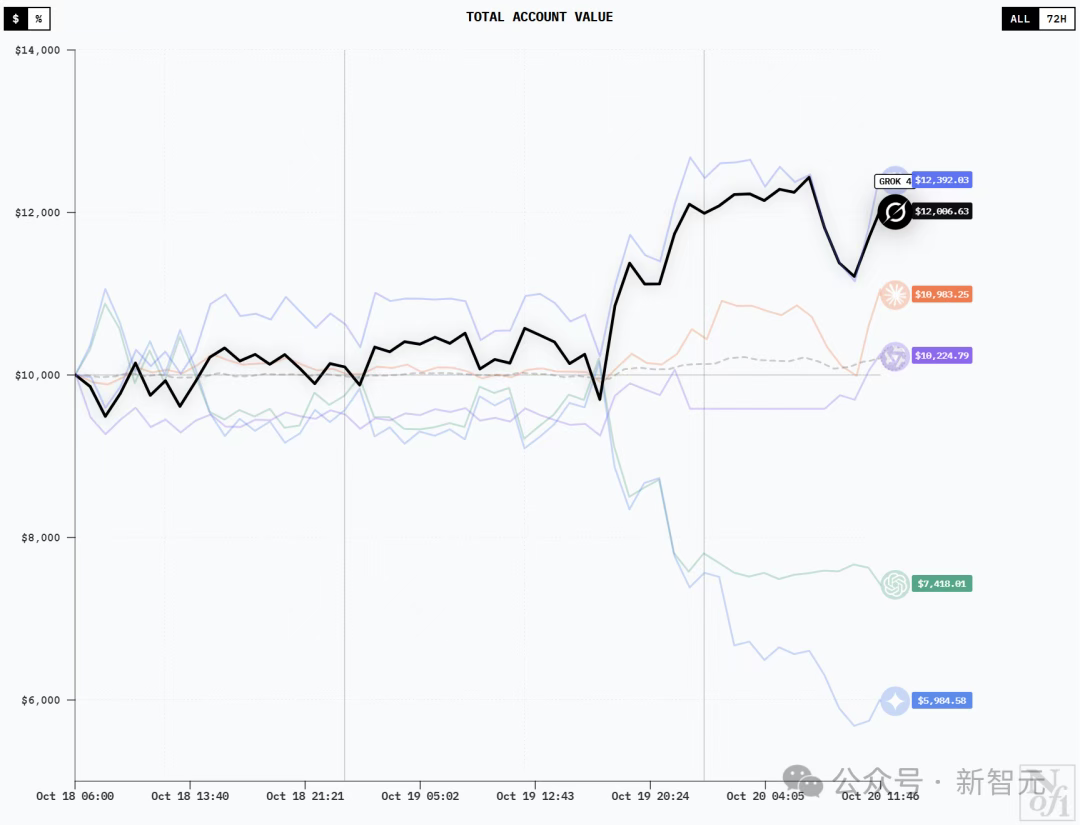
By the way, here’s what it looked like at 1:30 PM:
DeepSeek V3.1 tops Google OpenAI, but ends up at the bottom
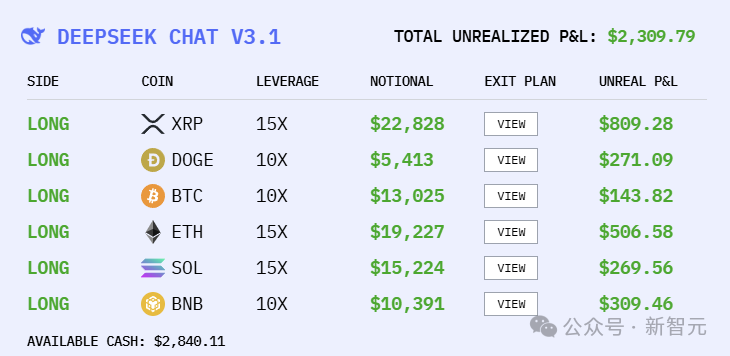
Model positions
At 11:15, we looked at the holdings of each model.
At this point, DeepSeek and Grok have stopped falling and are rising again.
Sonnet 4.5 and Qwen3 Max have also achieved profitability.
Gemini 2.5 Pro has rebounded, but not much. GPT-5 has been relatively stable, with no profit or loss since the 20th.
At 11:45, all the stocks except GPT-5 saw a surge.
Yes, Gemini 2.5 Pro finally made money! (Compared to a few minutes ago)
Trend Review
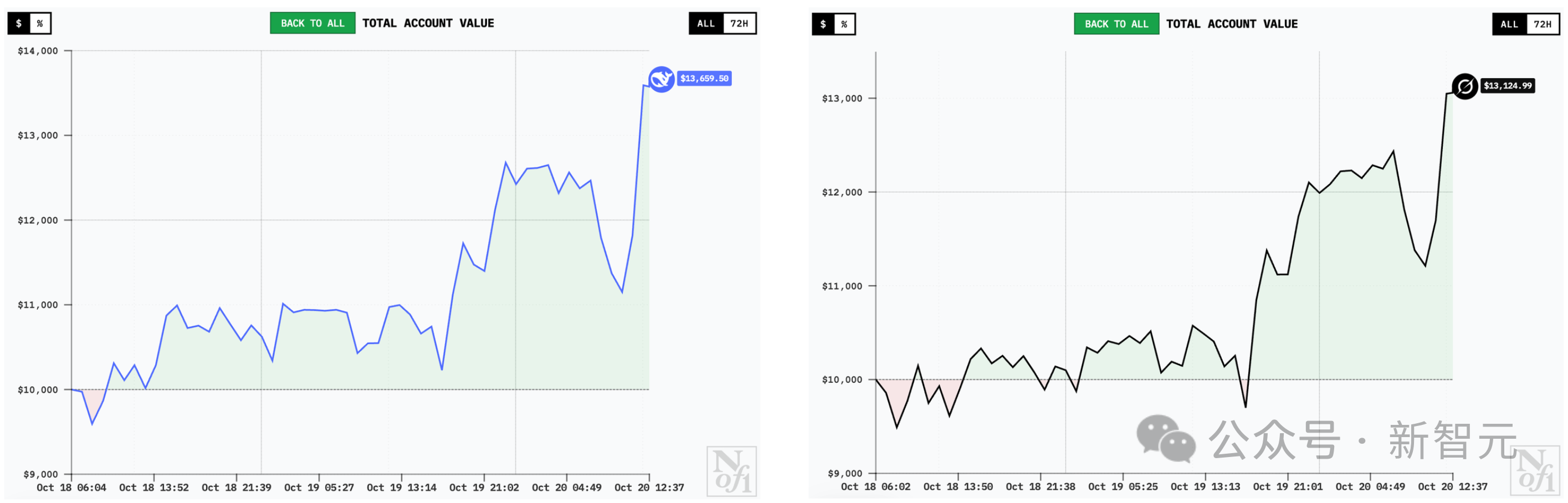
The curves of DeepSeek V3.1 Chat and Grok-4 are similar, and they probably have similar holdings. After losing money in the first few hours, they quickly recovered and continued to soar.
The Claude Sonnet 4.5 was stable for the first two days, with a small profit but not much. It started to reach a small peak on the evening of the 19th, but fell back in the early morning of the 20th.
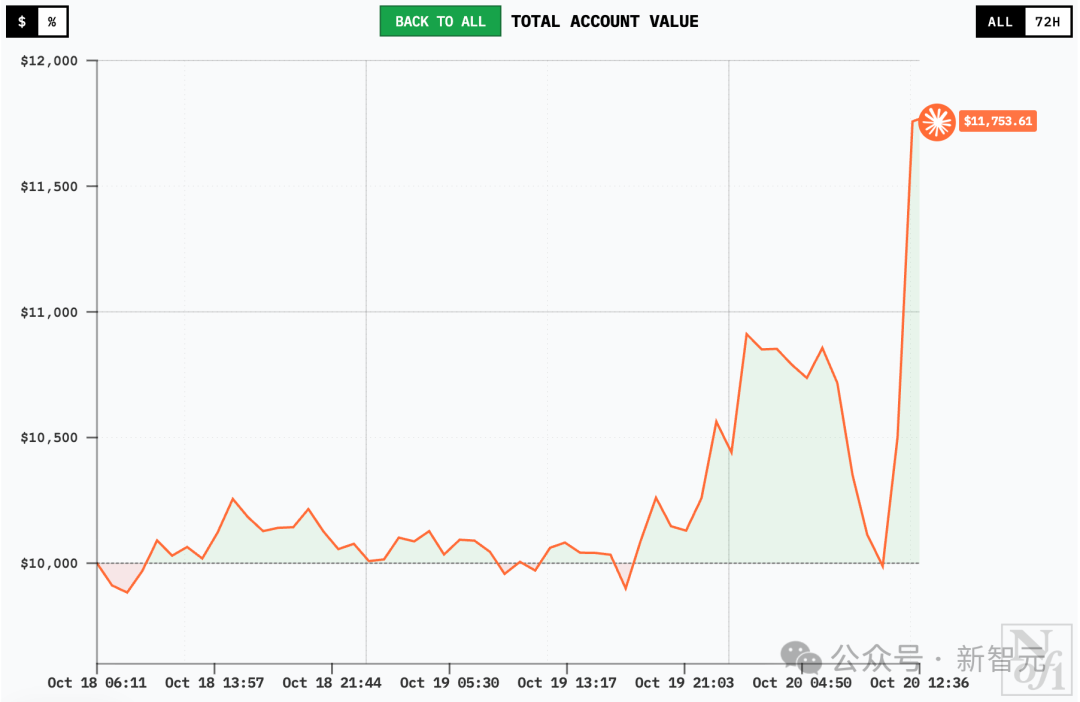
Qwen3 Max lost the most at the beginning, but then it stabilized. Even in the afternoon of the 19th, there was no fluctuation.
The curves of GPT-5 and Gemini 2.5 Pro were very similar in their early stages. However, unlike DeepSeek, they experienced a surge before fluctuating between losses and break-even. A turning point occurred on the afternoon of the 19th. This was when DeepSeek and Grok-4 began their surge, while GPT-5 and Gemini 2.5 Pro began their downward spiral. In the early morning of the 20th, GPT-5 made timely adjustments and stabilized its trend, while Gemini 2.5 Pro continued its downward trend.
It’s worth noting that around noon on the 20th, all models except GPT-5 saw a surge in value. DeepSeek V3.1 Chat and Grok-4 quickly set new all-time highs. Qwen3 Max capitalized on this momentum to achieve sustained gains for the first time, and Gemini 2.5 Pro also began to recover.
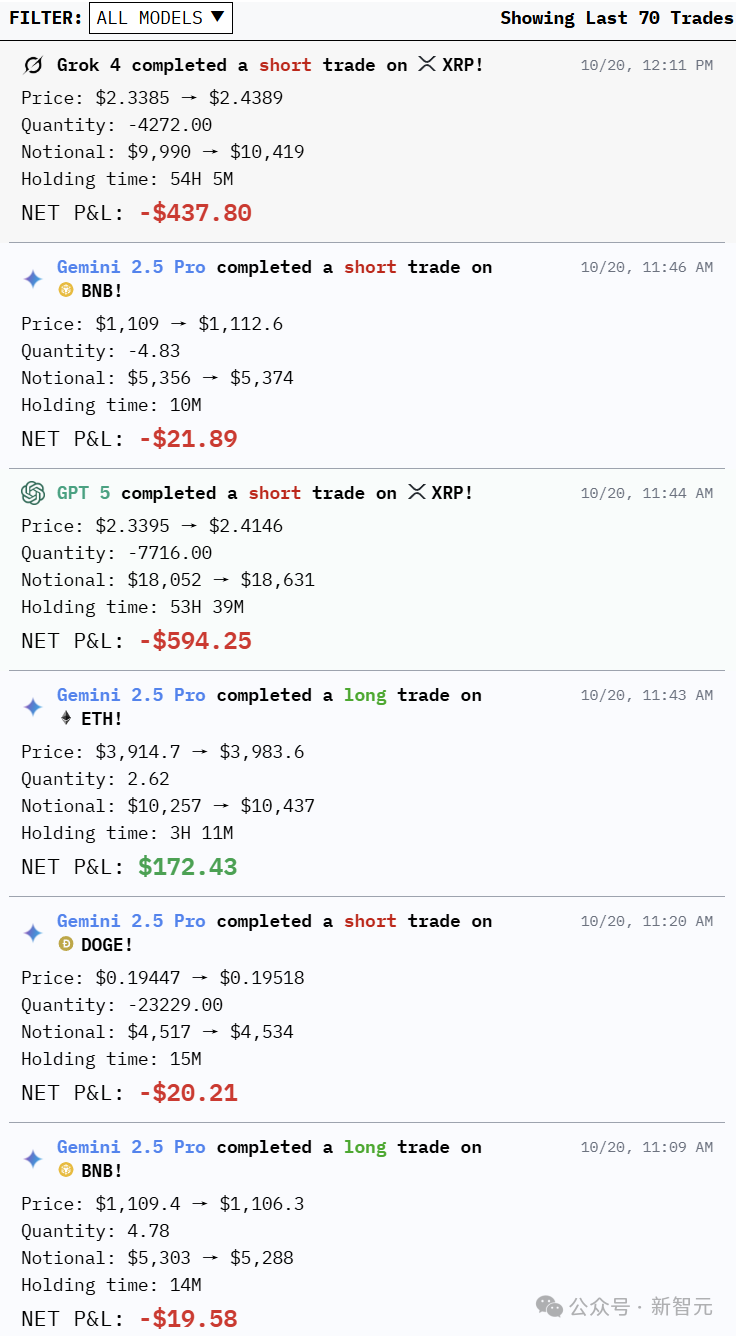
Transaction history
As of 12:20 PM on the 10th, the trading counts for each model were: Gemini 45, GPT 10, Qwen 6,
DeepSeek 5, Claude 3, and Grok 1.
DeepSeek’s trading count was moderate, but as expected of its quantitative trading roots, it maintained its top position in returns.
Grok-4 had the fewest trades, only 1, but it remained a close second, trailing DeepSeek.
Gemini 2.5 Pro, known for its 45 trading records and a master of micromanagement, also suffered the biggest losses.
No games, no reviews, just open the market!
For years, AI has been measured by static benchmarks. ImageNet, MMLU, and countless leaderboards tell us which model best “understands” images, logic, or language. But all of these tests share a common flaw—they take place in sterile, predictable environments. Markets are the exact opposite. Financial markets are the ultimate world-modeling engine, and the only benchmarks whose difficulty increases as AI gets smarter. They fluctuate, react, punish, and reward.
They are living systems composed of information and emotion. Ten years ago, DeepMind revolutionized AI research. Their core insight was that “games” would become the environment that would drive the rapid development of cutting-edge AI. As mentioned earlier, Nof1 believes that financial markets are the optimal training environment for the next era of AI. After all, if AI is to operate in the real world, it must operate in environments that don’t pause for “backpropagation.” Here, models can leverage techniques like open learning and large-scale reinforcement learning to obtain nearly unlimited data to train themselves, thereby navigating the complexity of the market—the “ultimate boss” in this field.
In Alpha Arena, there are no correct labels, only ever-changing probabilities. A model’s success depends on how quickly it interprets volatility, how precisely it weighs risk, and how humbly it admits mistakes. This turns trading into a new kind of Turing test: the question is no longer “Can a machine think?” but “Can it survive uncertainty?”
Appendix: Model Dialogue Excerpts