Lumina-mGPT 2.0: A resurgence of autoregressive models, rivaling state-of-the-art diffusion models
he Shanghai Artificial Intelligence Laboratory and other teams proposed Lumina-mGPT 2.0 – a standalone, decoder-only autoregressive model that unifies a wide range of tasks including text-based graphs, image pair generation, agent-driven generation, multi-round image editing, controllable generation, and dense prediction.

Core Technologies and Breakthroughs
Completely Independent Training Architecture
Unlike traditional approaches that rely on pre-trained weights, Lumina-mGPT 2.0 utilizes a decoder-only Transformer architecture, enabling completely independent training from parameter initialization onward. This offers three key advantages: unrestricted architectural design (two versions with 2 billion and 7 billion parameters are available), circumventing licensing restrictions (such as Chameleon’s copyright issues), and mitigating the inherent bias of pre-trained models.
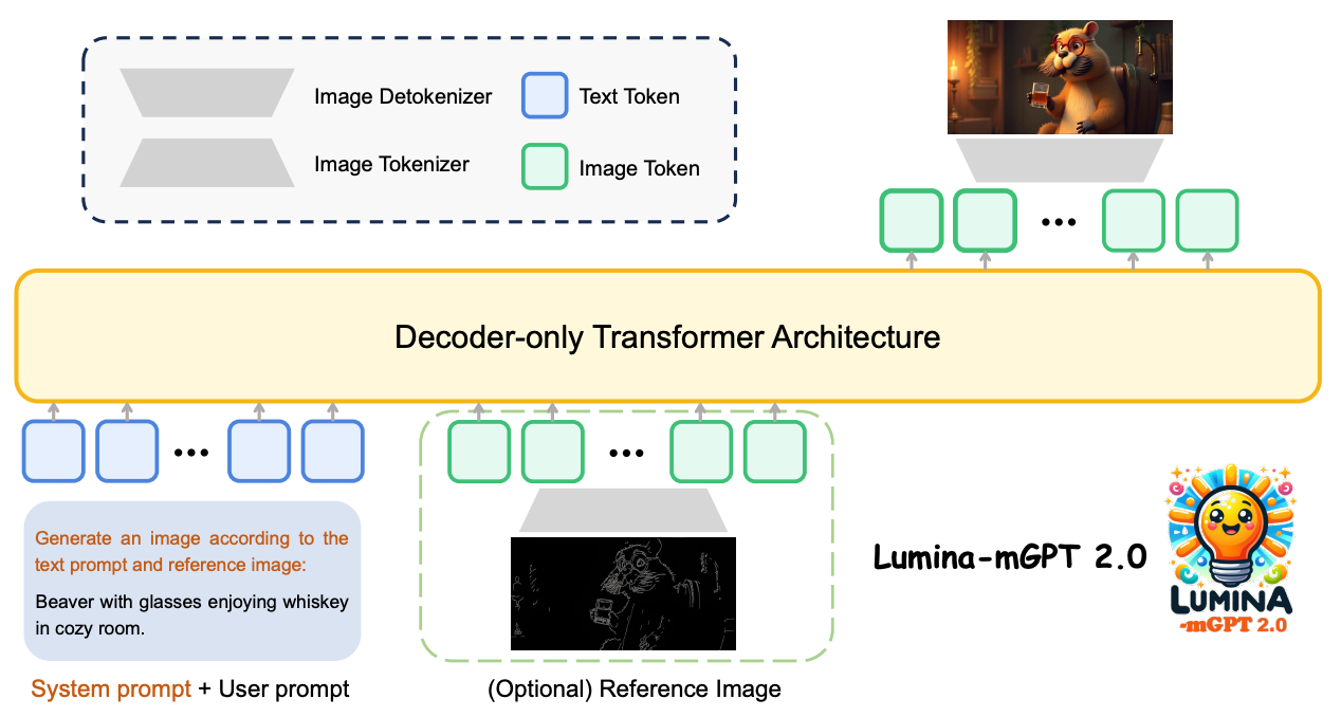
For image word segmentation, after comparing various solutions such as VQGAN and ViT-VQGAN, we ultimately chose SBER-MoVQGAN, which achieved the best reconstruction quality on the MS-COCO dataset, laying the foundation for high-quality generation.
Unified Multi-Task Processing Framework
An innovative unified image segmentation scheme treats image-based tasks as a single image by stitching them together. This is controlled through prompt descriptions, achieving consistency between multi-task training and text-based image training. This enables a single model to seamlessly support the following tasks:
- Text-based images
- Subject-driven generation
- Image editing
- Controllable generation (e.g., contour-based/depth-based generation)
- Dense prediction
This design avoids the tedious switching between different frameworks required by traditional models, allowing flexible control of task types through system prompts.

Efficient Inference Strategy
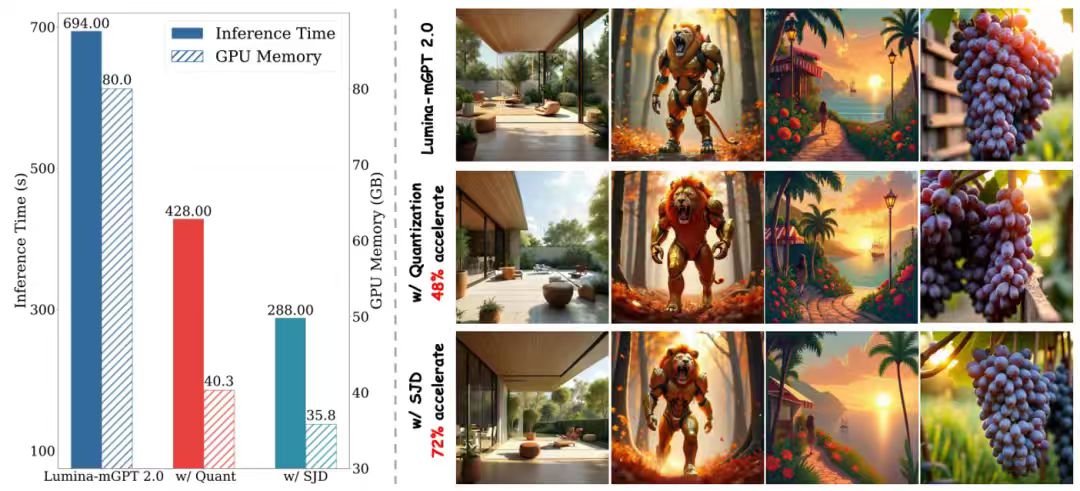
To address the slow generation speed of autoregressive models, the team introduced two optimizations:
- Model Quantization: Quantizes model weights to 4-bit integers while maintaining activation tensors as bfloat16. This optimization is achieved without changing the model architecture using native compilation tools in PyTorch 2.0 and the reduce-overhead mode of torch.compile.
- Speculative Jacobi Sampling: Utilizing a static KV cache and static causal attention mask, SJD is compatible with static compilation frameworks, accelerating sampling while avoiding dynamic cache adjustments. Combined with 4-bit quantization, this reduces GPU memory usage by 60% and accelerates generation through parallel decoding.
Experiments show that the optimized model significantly improves generation efficiency while maintaining quality.
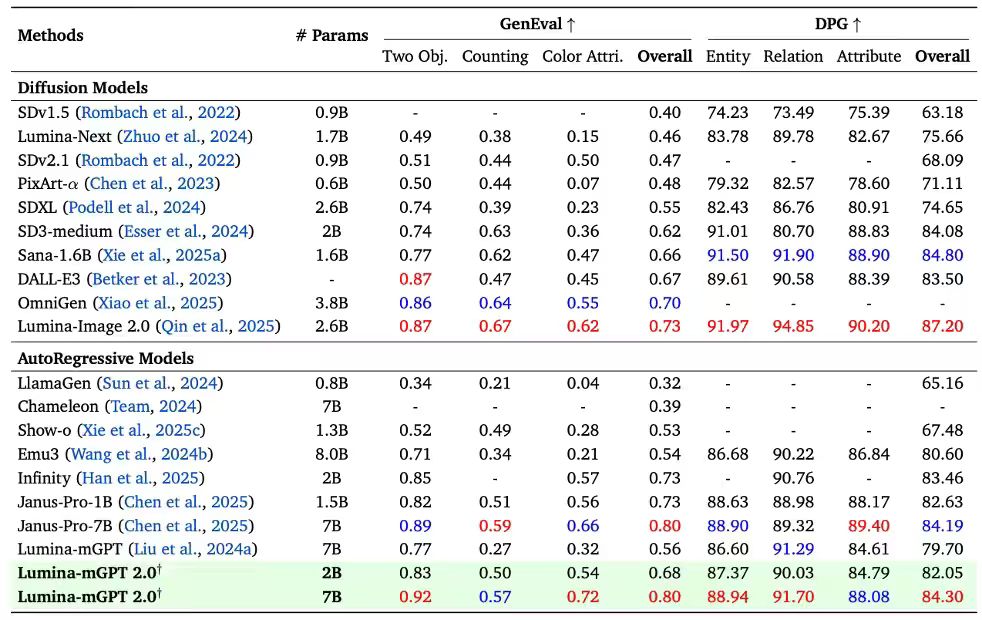
Text-to-Image Experimental Results
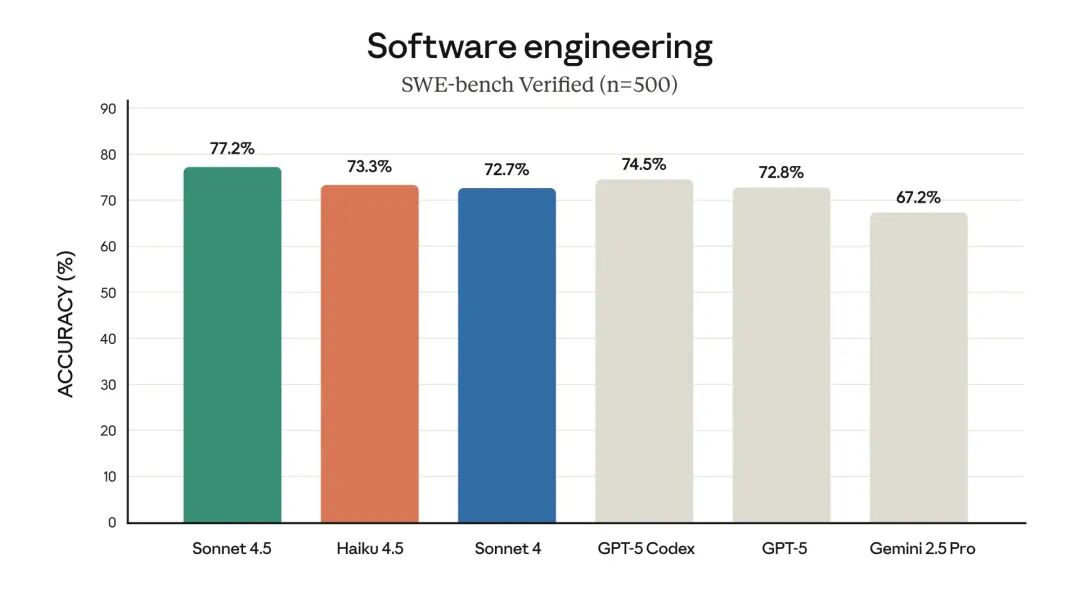
In the field of text-to-image generation, Lumina-mGPT 2.0 achieved outstanding performance across multiple benchmarks, matching or even surpassing diffusion and autoregressive models such as SANA and Janus Pro. It particularly excelled in the “Two Objects” and “Color Attributes” tests, achieving a GenEval score of 0.80 and placing it among the top generative models.
In addition, in terms of actual generated effects, Lumina-mGPT 2.0 outperforms its predecessors Lumina-mGPT and Janus Pro in terms of realism, detail, and coherence, and is more visually appealing and natural.

Multi-Task Experimental Results
Lumina-mGPT 2.0 achieved excellent performance on the Graph200K multi-task benchmark (controllable generation and object-driven generation), demonstrating the feasibility of using a purely autoregressive model to
address multimodal generation tasks within a single framework.
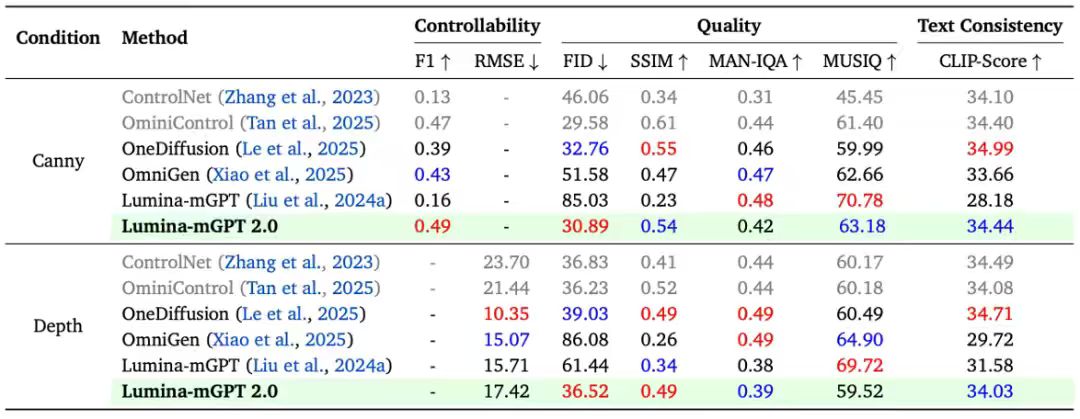
In addition, the team conducted practical comparisons with other multi-task generation models. Lumina-mGPT 2.0 performed outstandingly in controllable generation and topic-driven generation tasks, demonstrating excellent generation capabilities and flexibility compared to models such as Lumina-mGPT, OneDiffusion, and OmniGen.

Future Directions
Even after optimizing inference, Lumina-mGPT 2.0 still suffers from long sampling times, similar to other autoregressive-based generative models. This impacts user experience and will be further optimized in the future. Currently, Lumina-mGPT 2.0 focuses on multimodal generation, but plans are in place to expand its scope to multimodal understanding to improve its overall functionality and performance. This will make Lumina-mGPT 2.0 even more comprehensive in meeting user needs.
© Copyright notes
The copyright of the article belongs to the author, please do not reprint without permission.