1. The Pain Points of Traditional Models
-
Feeding a 500-page contract, a Nature paper with 30 pages of equations, or years of chat logs into an AI. -
The AI splits them into tiny “tokens.” More text = more tokens = slower processing (like a phone running out of RAM).
-
A corporate annual report: 200+ pages -
A research paper: 50+ pages of formulas -
Technical manuals: 100+ pages of code
-
Text-heavy files become compact image tokens (e.g., a 20-page paper → 256 visual tokens). -
Solves memory bottlenecks andpreserves context.
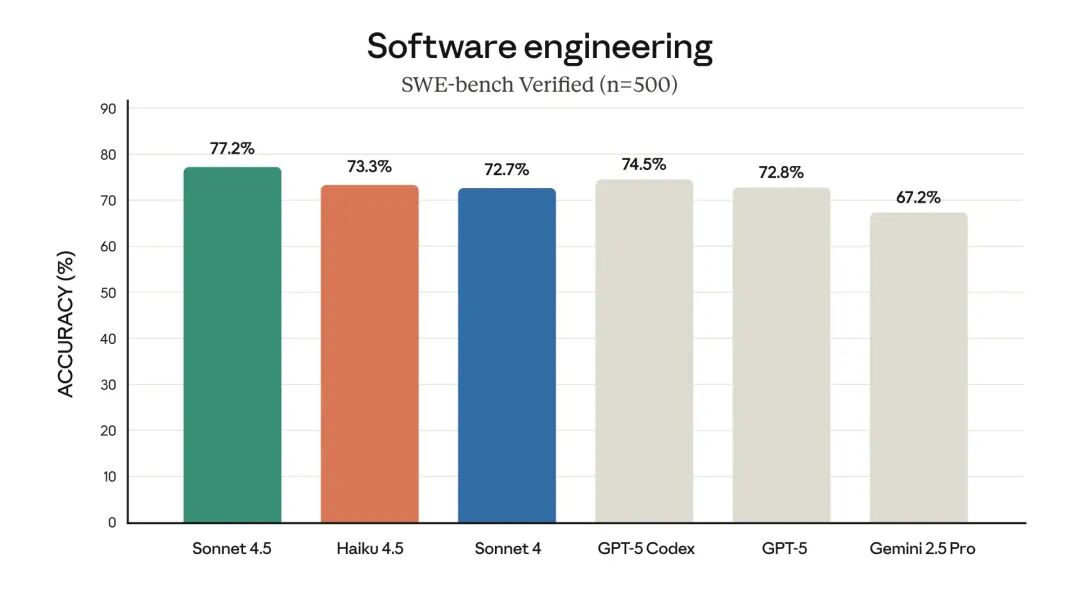
2. Mind-Blowing Benchmarks
-
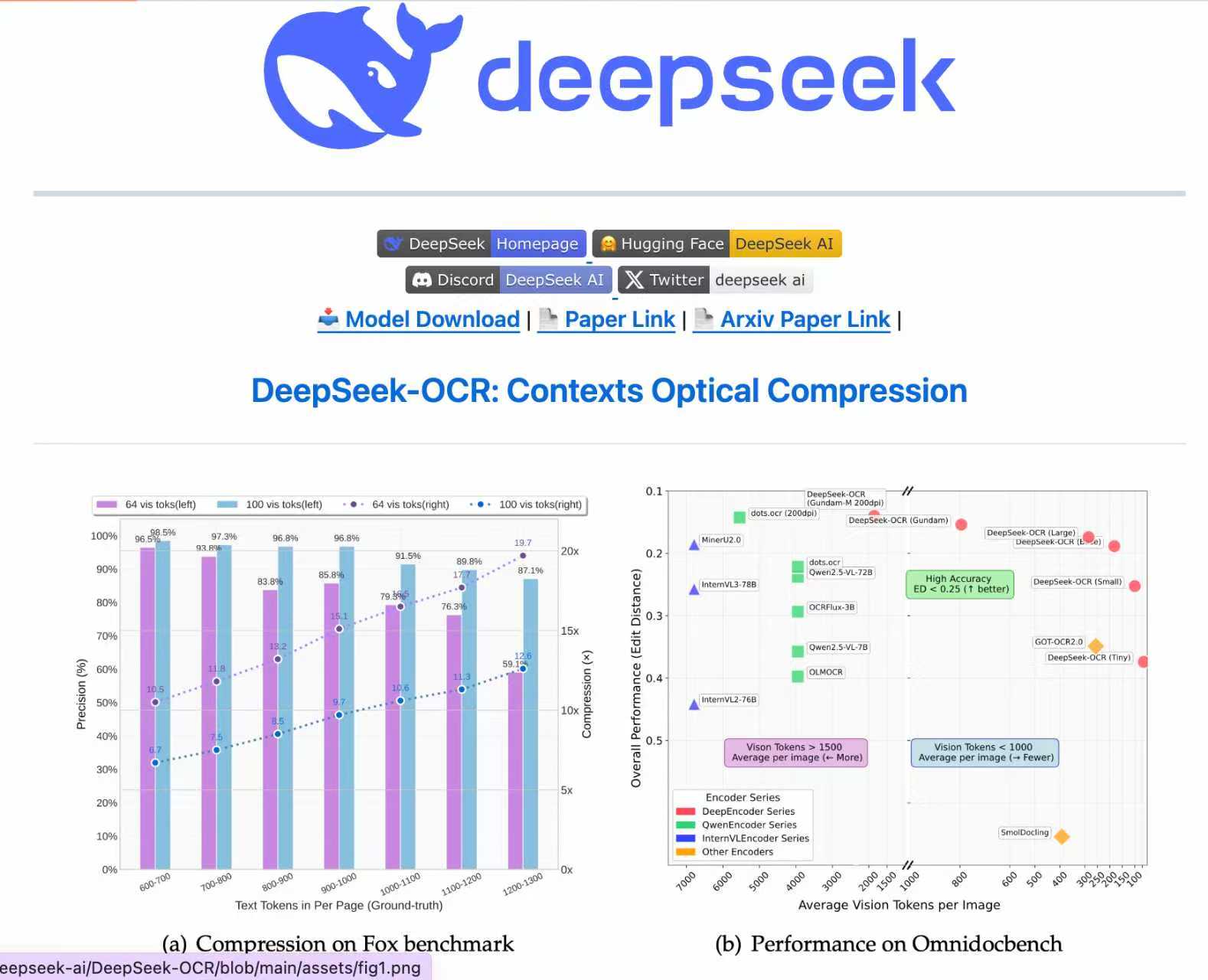
Fox Dataset: 10x compression retains 95%+ accuracy (near-lossless). -
700–800 tokens compressed to 100 visual tokens → 97.3% accuracy. -
1,200–1,300 tokens → 87.1% accuracy (still usable.
-
-
ICDAR 2023: Crushed competitors with 256 tokens/page (10x compression), 97.3% accuracy, and 8.2 pages/sec processing speed (only 4.5GB GPU memory).
-
286-page Annual Report: -
Table reconstruction: 95.7% accuracy (error <0.3%). -
Time: 4 mins 12 sec (vs. MinerU2.0’s 29 mins with 18.2% data gaps).
-
-
62-page Nature Paper: -
45 complex formulas recognized with 92.1% accuracy. -
LaTeX output: copy-paste ready.
-
3. How Does DeepSeek-OCR Work?
-
DeepEncoder (Visual Compression): -
Processes high-res images (e.g., 1024×1024 pixels). -
Compresses text into tiny visual tokens (e.g., a 20-page paper → 256 tokens). -
Cost-effective: Avoids GPU overheating.
-
-
DeepSeek3B-MoE-A570M (Decompression): -
Uses Mixture-of-Experts (MoE) technology, activating only 570M parameters. -
Reconstructs text from visual tokens.
-
4. Limitations
-
Compression over 30x drops accuracy below 45% (avoid legal/medical use cases). -
Complex graphics (3D charts, handwritten text) lag behind printed text by 12–18%.
5. Why This Matters
© Copyright notes
The copyright of the article belongs to the author, please do not reprint without permission.